
1. Introduction
The constant increase of popularity of Large Language Models (LLMs) is attracting more and more companies every day. If you have anything to do with the IT field, it's more than probable that you've heard about someone doing some kind of project involving an LLM. Maybe you are the one working on it.
Whether it be for chatbot applications, or as a component inside a larger pipeline, professional use of LLMs in business always comes back to giving the LLM some input, and expecting it to output an answer in a specific format.
We will focus more on the 'pipeline' scenario in this article. The reason? Chatbot scenarios are often easier when it comes to make the LLM answer the way you need it to, because the notion of "what makes a good answer" is broader.
The real struggle comes when you want to integrate the LLM as a component inside a larger pipeline, i.e., when the input comes from a previous component, and most importantly, the model's output is fed to a latter component.
2. A case example
For the sake of explanation, let's imagine we have a SQL database with a set of comments written by people, and we need to make sentiment classification on them. We could employ many techniques to achieve this, but suppose our manager tells us to do this with a Language Model.
The pipeline would be somewhat similar to this:
- Fetch a comment from the database.
- Feed it to the LLM and ask it to output the sentiment.
- Take the LLM's answer and insert it in the
sentimentfield of that message using SQL.
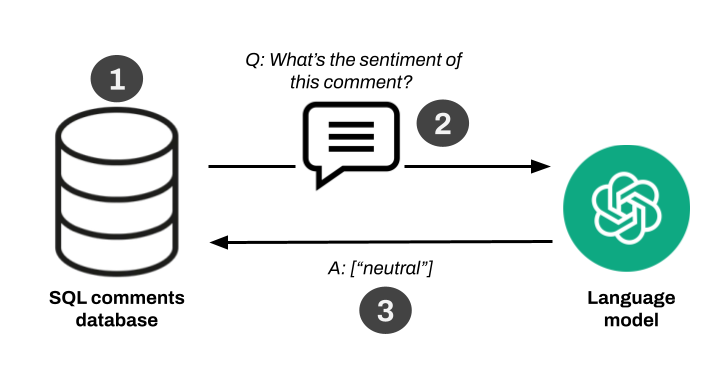
Cases like this are the bread-and-butter in business scenarios where LLMs are applied. Of course, they can be more complex. For example, you may want to extract a fixed schema of data from a PDF, instead of just a 'sentiment' keyword.
The real challenge appears in step 3. LLMs are naturally non-deterministic in their answers, so how can we assure the output will always be in the same format? When inserting a new sentiment on a database, we need it to stay on a fixed ontology (for example: ['Bad', 'Neutral', 'Good']), so the LLM should not create new categories on its own (such as 'Positive'). Also, the output should be constrained to just the sentiment category. The model shouldn't answer something like:
➡ The sentiment for the given comment is: Bad
But instead it should only output:
➡ Bad
Or even better, it should structure its answer in JSON format, which is easier to parse:
➡ {'sentiment': 'Bad'}
LLMs are good in answering like the first example, but we want them to behave like the third.
Achieving this kind of precision and consistency in the model's output is crucial in order to integrate it into the pipeline, before another process takes the output and inserts it in the SQL database.
If you spend any amount of time trying to figure this out by yourself, you'll find countless websites repeating the same basic tips, but if you want to discover more advanced ways of "taming LLMs", you'll have to dive deeper. This was my situation a year ago. Because of it, the purpose of this article is to share some "pro-tips for taming LLMs" that I've discovered through my journey.
3. Pro-tips for taming LLMs
3.1. KISS your prompts
Since generative AI models began to become mainstream, every now and then you see journalists talking about how "prompt engineers" will be the job of the future. Regardless of this being true or false, it is certain that you must learn how LLMs understand the inputs (prompts) in order to make yourself understandable.
But from what I've seen in myself and my colleagues, in the beginning we tend to make our prompts rather long, specifying every rule the LLM must follow with a lot of detail. I'll use a late motif to make this clear:
Keep It Simple, Stupid
If you wanted the model to output steps for a cake recipe, would you write this prompt?
➡ You are an assistant to write food recipes. Your task is to give the user a detailed list of steps to follow in order to make a cake. You must answer using the numbered-list markdown format.
Or would you rather just use this one?
➡ Here you have a detailed cake recipe:
1.
The 1. here is called a cue, and they are a super useful tool that not many people point out when talking about prompt engineering. Why does it work? At a high level, LLMs are just prediction models. They predict the next most likely word to follow a given sequence. That's it. So if you end your prompt with 1., you're giving the model a good clue that what follows is a numbered list.
Both prompts will probably work with most models for this toy example. But if you switch the cake recipe for a more complex scenario, you'll often end up with long and confusing prompts. I'll say it again, keep it simple, stupid.
Furthermore, if you need the LLM to work in a certain language, just write your prompt in that language! The odds of the model answering in Spanish are a lot higher if you just write the entire prompt in Spanish, rather than telling it to "answer in Spanish" (of course, the model you employ must have been trained with a corpus in the Spanish language).
3.2. Leverage JSON formatting capabilities

Returning to the sentiment classification case example, if you need to take the LLM's output and insert it onto a database, it would be a lot more helpful if the model already gave you an answer in a format you can parse. JSON is such a format. Like I already said, it is better to have the model output something like this:
{'sentiment': 'Bad'}
Than this:
The sentiment for the given comment is: Bad
(this way, you'll just have to usejson.loads()to get the'sentiment'field and insert it into SQL.)
Making LLMs answer in JSON can be a tricky task. First, you need the JSON to be in the same schema between answers. And, most importantly, the LLM should only output a JSON string, and nothing more like "Sure, here's your answer in JSON: {...}".
The quick answer is that some models are better than others when dealing with this. For example, GPT-4o performs better than its predecessors on structuring output. Another option I personally like is the Mixtral open-source model. You can install it on-premise, or use it through online APIs like Groq or OpenRouter.
The cool thing about Mixtral is, the folks who trained it included a parameter to force the model to output just in JSON format (GPT-4o also allows for something similar on its API). For example:
[Input]
import json
from mistralai.client import MistralClient
from mistralai.models.chat_completion import ChatMessage
prompt = f"""
Extract information from the following medical notes:
{MEDICAL_NOTES}
Return json format with the following JSON schema:
{{
"age": {{
"type": "integer"
}},
"weight": {{
"type": "integer"
}},
"diagnosis": {{
"type": "string",
"enum": ["migraine", "diabetes", "arthritis", "acne"]
}}
}}
"""
client = MistralClient(api_key=<api_key>)
messages = [ChatMessage(role="user", content=user_message)]
chat_response = client.chat(
model=model,
messages=messages,
response_format={"type": "json_object"} # FORCE the model to output in JSON format
)
response = chat_response.choices[0].message.content
response = json.loads(response)
[Output]
{'age': 34, 'weight': '123 lbs', 'diagnosis': 'diabetes'}
In the example above, we specify the JSON schema to use (the age, weight and diagnosis keys). By passing the response_format={"type": "json_object"}, the model is forced to output in a consistent JSON format, following the given schema.
If you want to delve deeper, this course by DeepLearning.AI explains how to properly use Mixtral with a lot more detail (jump to Lesson 2 to read about JSON formatting).
One last important thing about JSON formatting: make sure you tell the model what to output if it doesn't know the answer! LLMs tend to make up their own answers if what you asked for is not found in the input (for example, in a RAG application). This is called hallucination. If you intend the JSON answer to be parsed and inserted into a SQL database, not found fields should be all set to null. So tell the LLM just that. In most cases it is sufficient to include a sentence like this in your prompt:
If you don not know the answer for any field, just set it to `null`.
Later we'll talk about Pydantic models, where you can specify default behaviors.
3.3. Use few-shot examples
There's a common tip among articles about prompt engineering: few-shot examples. That is, giving the model a couple of examples on how to correctly respond. This is a quick way of making the LLM learn about a specific topic or your specific use-case, whithout having to fine-tune it. The whole RAG (Retrieval-Augmented Generation) system is based on this. For example, if you want to teach the LLM how to assign sentiments to consumer reviews:
PROMPT = f"""Asign a sentiment to the given comment.
The sentiments you can choose from are: ['Negative', 'Positive']
Some examples are given:
- Great product, 10/10 ['Positive']
- Didn't work as expected ['Negative']
- Very useful ['Positive']
- It broke 3 days after purchase ['Negative']
User comment to classify: {user_comment}
Sentiment:
"""
(notice the cue at the end of the prompt, this way the LLM is more likely to output just the sentiment)
There's a variation of few-shot examples: giving both an example of a good answer, and an example of a bad one. I found this extremely useful when doing a project where I needed the answers to be in a strict JSON schema (this was before the time of open-source Mixtral, on the age of GPT-3.5). The way I achieved a high rate of consistent answers was combining positive & negative examples, and a cue:
PROMPT = f"""I need to extract the name of startup founders from this pitch deck:
{pitch_deck_text}
The output must be in the following JSON schema: {{'founders': [<LIST_OF_FOUNDERS>]}}
Positive example: "{{'founders': ['John Doe', 'Kelly Smith']}}"
Negative example: "The founders are John Doe and Kelly Smith"
Startup founders:
"""
Of course, if you want to achieve 100% consistent JSON output, I still strongly recommend using the Mixtral capabilities I talked about in the previous section. But if for some reason you're constrained to certain models (like GPT-3.5) this can be a good workaround.
3.4. Output Parsers
If you have worked any amount of time with LangChain, you'll probably be wondering at this point: "when are you talking about Output Parsers?".
In short, output parsers are a way of structuring the output of the LLM, so that it adjusts to a given schema. Of course, this is not a concept exclusive to LangChain (LlamaIndex also implements them). As I have only worked with LangChain, I'll talk about their implementation, though. They provide a curated list of different parsers, each returning a specific format: JSON, CSV, YAML...
As always, I prefer to use the JSON output parser, since JSON is an inter-operable format that is very versatile for ingesting it into multiple pipelines: chatbots, SQL databases... (a JSON object is so easy to parse with Python before doing an insert with SQLAlchemy).
But there's one other type of output parser worth mentioning, and that is the Pydantic parser. In essence, this output parser returns a Python object compatible with a Pydantic schema, which may be better for data validation when compared to plain JSON. Here's the example shown by LangChain on this parser's documentation:
[Input]
from typing import List
from langchain.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from langchain_openai import ChatOpenAI
class Actor(BaseModel):
name: str = Field(description="name of an actor")
film_names: List[str] = Field(description="list of names of films they starred in")
actor_query = "Generate the filmography for a random actor."
parser = PydanticOutputParser(pydantic_object=Actor)
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
chain.invoke({"query": actor_query})
[Output]
Actor(name='Tom Hanks', film_names=['Forrest Gump', 'Cast Away', 'Saving Private Ryan'])
This way you can leverage the LLM's JSON formatting capabilities along with Pydantic's features such as field validators to create a powerful extraction-structuring pipeline
In fact, I've recently found out that combining Pydantic parsers with the latest GPT models works especially well in document information extraction projects.
4. Conclusion
In this article, we've explored the challenges of integrating Large Language Models (LLMs) into business pipelines, where the output of the model needs to be in a specific format to be fed into subsequent components. We've discussed the importance of "taming" LLMs to behave as desired, which can be summarized in the following pro-tips, which may be followed in order:
- Keep your prompts simple (remember, cues can be your friends!). This is the single most important rule to follow when working with LLMs, no matter what your goal is.
- Leverage JSON formatting capabilites, which are already a built-in feature in models such as Mixtral or GPT.
- When working with LangChain (or LlamaIndex), use the Pydantic / JSON output parsers.
- As a last resort, use few-shot example prompting to tell the model how a good structured output is like (and, also, how a bad output is like).
By applying these techniques, you can increase the precision and consistency of your LLM's output, making it easier to integrate into your pipeline. Whether you're working on sentiment classification, data extraction, or other applications, these tips will help you harness the power of LLMs to drive business value.

.jpeg)
